
How Google Search Works?
Have you ever wondered how your search query returns with the desired search result within few seconds? There’s a whole lot that goes behind the results that appear in a matter of few seconds. One post won’t be adequate to explain everything but we’ll try to break it down to simplify things for you.
The Google bots explore a billion web pages on the internet, which are rendered and indexed carefully to present the user with the most relevant results. But what do the terms crawling and indexing mean? Don’t worry, we’ll help you with understanding these basics of Google search.
What is Crawling?
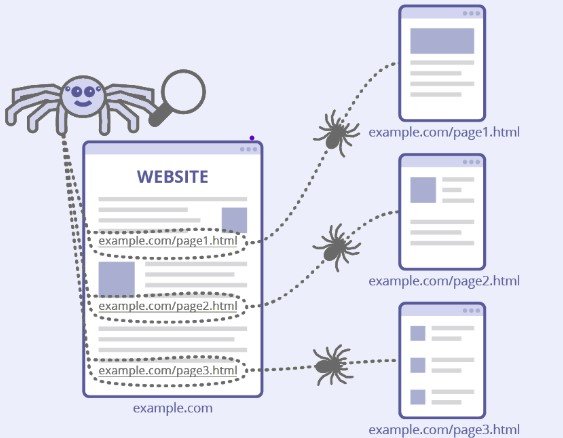
Google has a mammoth set of computers whose main task is to crawl and fetch all the information available on the internet. In this process, the new and updated websites are crawled regularly. These crawlers are also known as robots, spiders, and bots. The algorithm on which these bots work determines which pages are to be crawled and how often. These bots leverage sitemaps submitted by website owners as well as a list of previously crawled URLs to add newly discovered pages to their list.
Google uses two different crawlers —Primary Crawler and Secondary Crawler. The two simulation crawlers used are mobile crawler and desktop crawler. Both these crawlers i.e. mobile and desktop imitate the users experience on the website on mobile and desktop. The primary crawler for new websites is the mobile crawler, which crawls webpages that haven’t been crawled before. The desktop crawler is used for recrawling, which crawls pages that have already been crawled to see how well pages perform on different devices.
What is Indexing?
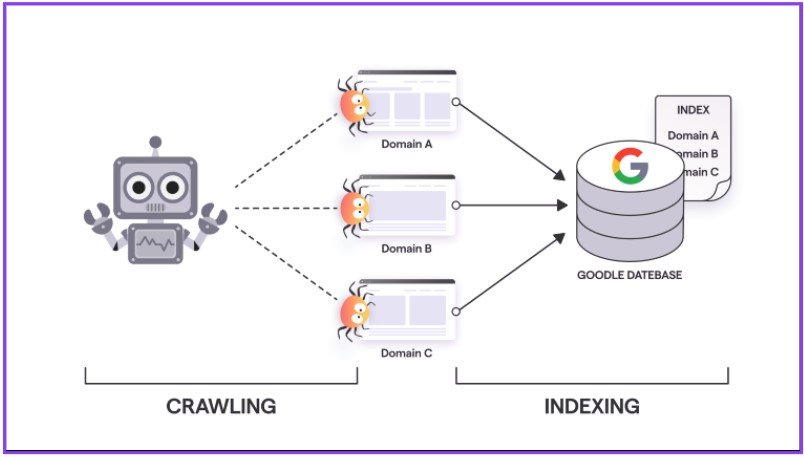
To understand what the content of a page is, Google bot has to process each page that it crawls. These bots need to understand the context of the web pages to display the relevant information. A user searching for the origin of dogs doesn’t want to be displayed with results of dog food items or movies related to them. That’s why indexing becomes crucial. In this process, the key content tags and attributes, textual content, images, videos, etc. are processed. Although it can’t process all content types such as rich media files.
In some cases, you might not want Google to index a particular page because of its irrelevancy for the user. Pages that have a ‘noindex’ tag will be skipped in the process of crawling. But a point to note is, if a page is already blocked by robots.txt file, do not include the ‘noindex’ tag because Google won’t be able to see the tag, and the page still might get indexed! You can improve the indexing of your pages with structured data.
Between both crawling and indexing, Google also looks for duplicate or canonical pages. Duplicate pages could be due to various reasons such as URLs created to support multiple devices or to support content for www/HTTP/HTTPS variants. For Google, these multiple URLs though important will be considered as duplicates. For this purpose, it will choose one among them that it considers being informative as the canonical version. The duplicate URLs will be crawled less often than the canonical version.
This detailed post is only to give you a glimpse into the backdoor happenings of how a google search works. Google is updating its algorithm with minor tweaks, prompting us to rethink our current techniques for the ultimate goal of ranking higher on the Search Engine Results Page(SERP). Crawling and indexing a website also depends on how effectively your website functions. One such aspect is Technical SEO which is the proper optimization of the website by paying careful attention to necessary elements corresponding to ranking factors.
Spread the knowledge!
Follow TechVint on social media, where we educate our followers on a variety of digital topics: Facebook, Instagram, Twitter, LinkedIn
Get more knowledge bombs: How To Do Keyword Research For SEO